Football Stats Quiz

About a month ago I watched a very awesome and inspirational talk by Patrick Lucey from StatsPerform on an overview of AI in sport. In one of their slides th...
About a month ago I watched a very awesome and inspirational talk by Patrick Lucey from StatsPerform on an overview of AI in sport. In one of their slides th...
Last month the creator of the HydraNets course on multi-task learning Jeremy Cohen reached out to me and asked if I would be interested in speaking with him ...
I recently read the CVPR 2022 paper titled “Learning to generate line drawings that convey geometry and semantics”, and I found the results quite interesting...
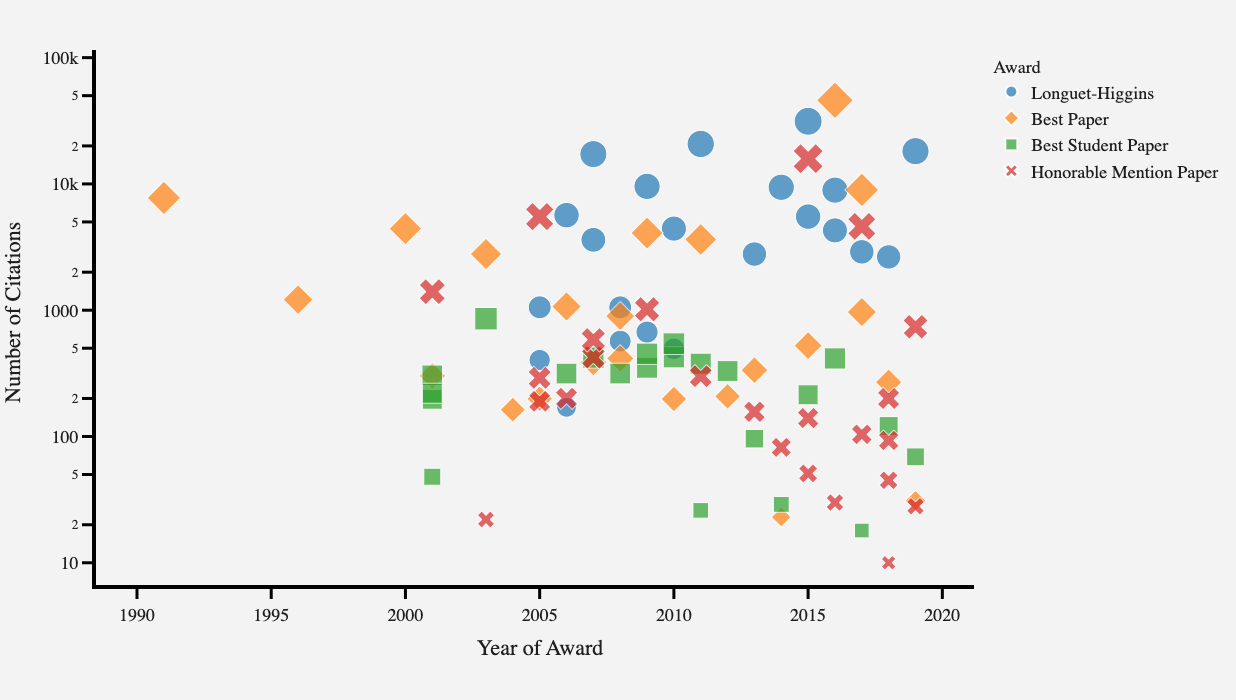
CVPR has long been regarded as the cream of the crop in the area of computer vision, attracting high-quality and influential publications. Traditionally, sev...
Recently I returned to Australia from the US where I had spent five months as an intern at Skydio, a Redwood City-based startup that is building autonomous f...