
Are we there yet? Part I. Education
As of 2019, if you were to build a text generator (akin to this one), chances are that after the word Artificial it would mostly likely be predicting the word Intelligence; that combination of words is currently everywhere – driverless cars, medical diagnosis, deep fakes, and on, and on. As a person that being fortunate to be doing research in related areas during this period, I would not call the underlying algorithms “AI” and instead would prefer such terms as machine learning, pattern recognition, data analysis and data science, or, more generally, not yet AI.
The first focus of the series of posts on not yet AI applications in real-world is on the education sector. The choice is not accidental, and the reason for it is two fold. On the one hand, I have personally spent 16 years being formally educated in schools and at my first University, 3 years and counting of doing my PhD, at the same time devoting a significant portion of my time over the last 7 years to self-education. On the other hand, I truthfully believe that the paradigm of creating intelligent machines must be soon shifted to the one of what we can learn from somewhat-intelligent machines, or what they can teach us. An interesting example is the usage of computer vision algorithms in the medical area: already some algorithms surpass human doctors in certain situations; hence the question to ask is how that happens? What can human doctors learn from those results? As of now we do not possess the answers with explainability still remaining a very active research area.
In today’s post I will walk through 4 companies, each in one way or another related to education. My goal is to explain (or rather to speculate) what problems these companies face and how they are leveraging algorithms in order to approach them. Few disclaimers before I start:
- first of all, I do not have any commercial interest with regards to any companies listed here; all the conclusions serve as my personal opinion; all information provided here was acquired through openly available sources;
- secondly, the list is not meant to be exclusive; I am happy to add more use cases;
- thirdly, I treated my review process of the listed companies as a set of pure exploratory observations.
LinguaLeo
The English language remains one of the most spoken languages in the world, hence there is no shortage of people interested in learning it. LinguaLeo is an online resource that facilitates that process via an educational application. The company has been around since 2010; I even remember using their app once or twice back in my Uni days in Moscow. It was pretty intuitive, but I felt that it was mostly aimed at the beginners.
In any case, their website tells me that their customer pool includes 17 million people. Given such a large number of users, it is quite a challenge to provide a unique educational experience for everyone without relying upon some algorithms (and even with). Unfortunately, the tab called About the service on the main page gives me the 404 error message. The version of the website in Russian contains the same information about the service: i.e., it provides "personalised solutions for customers learning English together with automatic evaluation of their progress". Pretty neat, right? I wonder how it is being done under the hood.
Searching on the web phrases like machine learning at LinguaLeo (both in English and Russian) does not lead me to anything. Fortunately, the search on a patent database returns two records. The first patent is called "System and method for automated teaching of languages based on frequency of syntactic models". Sounds interesting and relevant.
In a nutshell, the patent describes a common application of computational linguistics of parsing any given text into sentences, those into tokens (or words) and then into lemmas (a canonical form of a word), while identifying the syntactic model of a sentence and part-of-speech tags of words. For example, the sentence “I like red colour” can be described by a syntactic model “PRP VBP JJ NN”, where “PRP” stands for personal pronoun, “VBP” – verb, non-3rd person singular present, “JJ” – adjective, and “NN” – noun. Those syntactic models can be built for any sentence, and the system described in the patent is supposed to be generating a hierarchical tree-like structure of different model types that the user may learn from. In that way while studying a certain structure at some level in that tree, the user would be able to repeat previously learned structures – i.e., those above the current level. During the learning process, the user is asked to provide a correct completion of a given sentence that follows a particular syntactic model; the choices consist of so-called trick words: "trick words may include, but not limited to synonyms, pronouns, phonetically similar words, different verb tenses, plural forms, auxiliary verbs, comparative and superlative adjectives, etc.", while "for pronouns and certain other words, trick words may be taken from previously prepared lists.". After a certain number of sentences are correctly filled-in by the user, "the given syntactic model may be considered to have been learned by the user.". Below is one example of the described system that should make my explanation clearer:
 |
|---|
| Example of trick words from the Lingualeo patent |
The second patent is titled "Crowd-sourced automated vocabulary learning system". This time the underlying algorithm simply stores words along with their translation and context information that the user has chosen – think of it in the words of the inventors as "an individual learning dictionary". When a sufficiently large number of users has added a certain word with different contexts and translation into their own dictionary, the underlying global dictionary can be improved by using certain machine learning algorithms that track the frequency of occurrences of each word in different contexts. The translation of the word selected by the user is acquired from a stored database, while the users also have an option of adding their own translations which would serve as a reference to the system. Each word and context have rankings influenced by the user choice. In a way that the system can teach users, the users can also influence the system, hence the term crowd-sourced. As for the learning process, it can be automated by asking the user to "provide a correct translation; listening to the word sound and writing a word; and listening to the word translation and typing a correct word.".
Due to the lack of other available information, I will conclude here by stating that in the mentioned patents LinguaLeo relies on commonly available computational linguistics techniques and algorithms that parse any given content into syntactic structures. The patents describe how given those structures and lemmatisation of words (or tokens), the underlying system would be able to present to the user different plausible forms of the same sentence while tracking the user progress on learning a certain syntactic form. In addition, the user can choose various contextual information to accompany any words in its personal dictionary. It is unclear to what extent the current LinguaLeo products rely on the systems described in the patents; furthermore, it would also be interesting to know whether their algorithms are leveraging any recent progress in natural language processing, and how much manual work is still required for creating their educational process.
Thinkster Math (prev. Tabtor Math)
The earliest content I found on Tabtor Math is this video from YouTube. Now the company is called Thinkster Math, and it is an on-line tutoring platform that focuses on teaching math to kids. As boldly stated on their main page, Thinkster Math is "Real Teachers + Groundbreaking AI". I am intrigued by the second part.
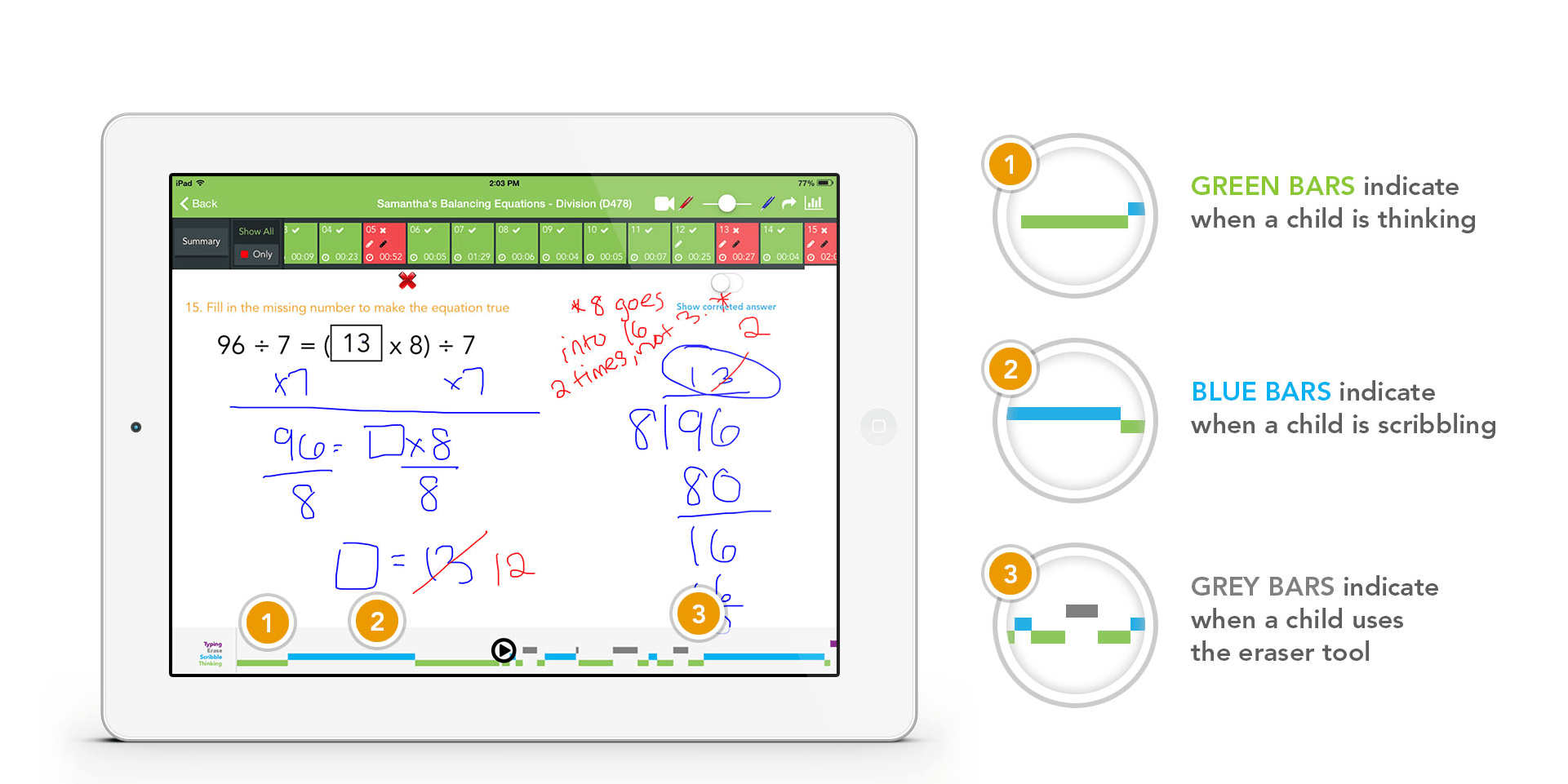
This time there is much more information on the product itself. The "Groundbreaking AI" is mentioned as point #6 on the About page: "Your child’s coach is able to visualize student thinking process and provide specific feedback on the questions answered incorrectly. Understanding “why” your child makes mistakes helps our teachers swiftly accelerate their learning." That understanding is carried out through "patent-pending Active Replay Technology (ART)" that records all the steps that the child took while answering a certain question. I find more information on "ART" on their website: "The artificial intelligence and machine learning in our math tutor app will show your child’s tutor how long they spent thinking, which numbers they wrote down first, how fast they worked toward their answers and much more.". As further written, "The ability to visualize student thinking – how fast they worked, where did they pause, what did they do before they erased their work and re-did their math – all happening at the point of learning".
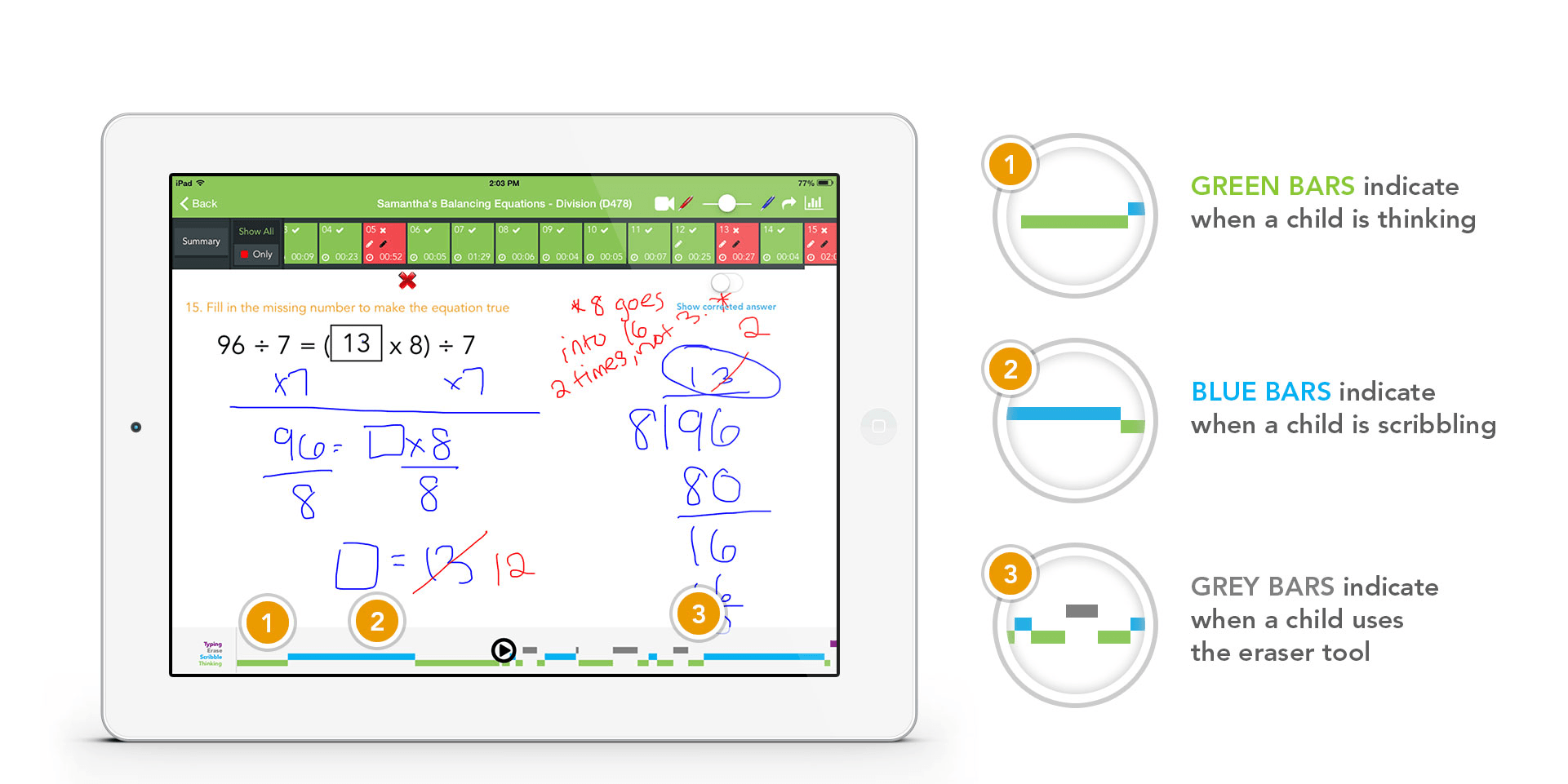 |
|---|
| Example of ThinksterMath app in action. Picture from ThinksterMath |
From the above it appears that the company is simply recording the process of solving a particular problem, with that information being later analysed by some underlying algorithms. This is succinctly delivered in the company’s blog: "The application records many data points when your students complete their work, such as the time that they take on each question and their accuracy. The AI then suggests assignments based on student performance. ... Ultimately, though, you make the decision on individualized learning plans for each student! AI-enabled insights just help you efficiently evaluate and modify the plan so that you work smartly and use your time wisely."
I did not find any more information on the company’s "groundbreaking AI", so I will stop here: from what I read, the company’s product reminds me of Google Analytics built for tutors – in effect, you gain an access to tracking the student progress and thinking process, but in the end all major decisions are still on you. This way the company does seem to simplify the working process for the tutors, but not directly the learning process of the kids.
Gradescope (acquired by Turnitin)
If you have ever done grading of student works, you know how time-consuming that process is: you have to read through all the works, make sure that your metrics are consistent (across the students and between different tutors), summarise all the results and then release them to the students. Finally, not everyone will like their grades so be ready to spend some additional time discussing the marks with the students.
But fear no more, as Gradescope developed what they call an "AI-assisted grading" system that facilitates the process by automating most of its stages (here I will only cover the way in which they achieve grade consistency). Even at the first glance, the company appears to be much more machine learning-oriented as evident by a significantly larger pool of information readily available on their “secret sauce”. This comes as no surprise as the company founders are computer science graduates from Berkeley (fun fact for robotics & RL folks: Pieter Abbeel is one of co-founders).
First of all, there are a couple of academic papers: Gradescope: a Fast, Flexible, and Fair System for Scalable
Assessment of Handwritten Work and How Do Professors Format Exams?
An Analysis of Question Variety at Scale. The major component described in the first paper is called "rubric": "Each rubric item has a point value and a description associated with it.... The rubric can be subtractive (rubric items correspond to point deductions, or mistakes), or additive (rubric items correspond to point additions), and it can have a point value floor and ceiling." Intuitively, rubric provides consistency between different tutors grading the works as all of them will be adding or subtracting points on the same basis; furthermore, as the authors write, the rubric items can be dynamically altered – e.g., when some item is missing or was incorrectly used; such a change will lead to automatic recalculation of all the scores. Another feature of the rubric is that it facilitates fast analysis of what kind of errors the students tend to make. The second paper builds upon the data acquired by Gradescope to analyse the effects between the exam structure and the students’ performance. It is mostly an exploratory data analysis without insights into the inner works of Gradescope, so I will leave it at that without a further discussion.
Apart from those papers, Gradescope also received a grant on developing a deep learning-based solution for automatic grading: "... project will show feasibility of a method for instant and accurate grading of student answers to a previously unseen question, after observing an instructor grade no more than 10% of the answers to that question." The grant abstract describes the solution as based on few-shot learning, a type of machine learning where the system must learn useful representation from only a handful of samples – e.g., given only few images of cats and dogs, it should be able to differentiate between a significantly larger pool of different breeds of cats and dogs. I did not find more information on that grant apart from the part in one of their blog posts stating that they "have already submitted a report ... to an academic conference".
As part of the process of automating the records of students’ answers in the system, Gradescope leverages a machine learning algorithm. As Pieter Abbeel explained in one of the first company posts, "the AI has been trained on tens of thousands of past student answers, and it managed to understand some pretty complicated things. For example, some students choose to mark by bubbling in, others by check-marks, and yet others by crossing off — the AI has no problem with any of these.". As also written in the same post "The AI analyzes student answers, and groups them based on similarity.". Such groupings, I believe, are quite a handy tool when grading hundreds of works.
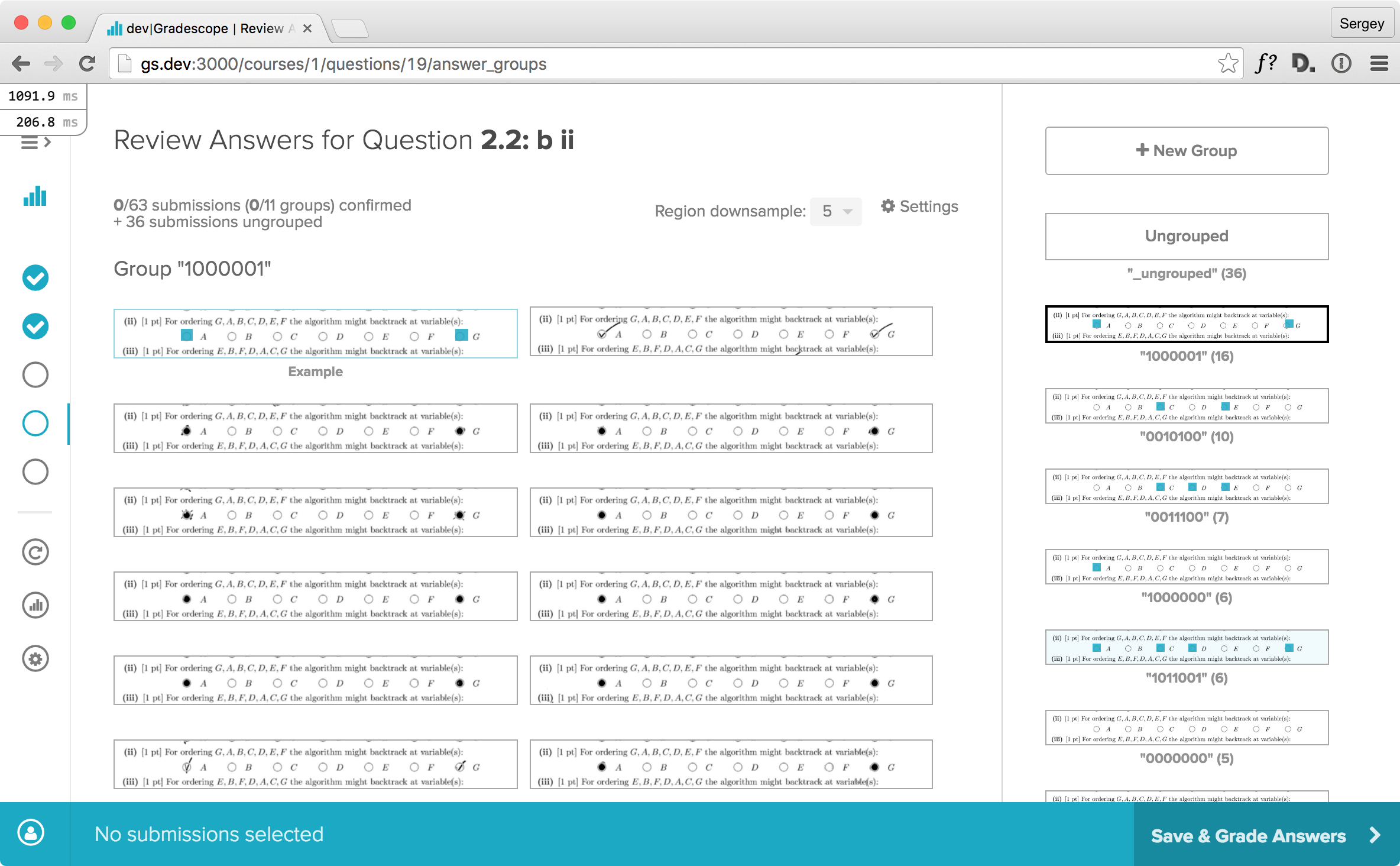 |
|---|
| Example of Gradescope app in action. Picture from Gradescope |
Overall, it appears to me that Gradescope was able to significantly automate the grading process by carefully approaching previously existing hurdles, primarily the inconsistency in the grading process itself. It would be definitely interesting to see whether their attempt on leveraging few-shot learning would bring even further automation in the grading process.
Duolingo
Duolingo is another platform for learning foreign languages and was founded in 2011. As LinguaLeo, it makes the learning process akin to a game. Opposed to LinguaLeo that claims 17M users, the Duolingo numbers are in hundreds of millions. Let us see what technologies they rely upon.
First of all, Duolingo has its own AI team, semi-regularly publishing their works and currently consisting of 12 people (when I started writing this blog two weeks ago there were only 11). For example, in the paper titled “Second Language Acquisition Modeling” the authors describe a dataset that was collected by Duolingo from the beginner-level users and that contains a large number of repetitive mistakes made by the users throughout the learning process. Such a dataset facilitates the forecasting of what potential errors the users would make in the future, which in turn would provide a chance to develop a more suitable curriculum to alleviate those errors.
Another paper, “A Trainable Spaced Repetition Model for Language Learning”, sheds more light onto the learning process provided by Duolingo. In particular, in it the authors study the effects of repetitive practice on the learning process. Duolingo tracks various statistics about the user learning process, for example, "how often learners answer a question correctly, how often they answer correctly without taking any hints, which words they take hints for, and how long the average learner spends completing a lesson.". Thus, the system knows which words are problematic for the user, so that it can decide to remind the user about a particular word. The important question to ask is when to remind the user? Obviously, if you show the user the word 10 minutes after it was learned, the chances are he or she would still remember it quite clearly. What about 10 days? As Duolingo explains in their blog post: "Our approach is based on the spacing effect: the finding that short practices spaced out over time is better for learning than "cramming." A related finding is the lag effect: you can learn even better if you gradually increase the spacing between practices. These ideas go back to 1885, when German psychologist Hermann Ebbinghaus pioneered the concept of the forgetting curve." In the paper, the authors propose to fit this forgetting curve for each word based on large amounts of collected user data, i.e. they relax the assumption that each user learns each word in the same way. This mathematical model is termed as "half-life regression (HLR)" and solves the problem of estimating the half-life of a word in the memory of the user. A nice feature of HLR is that it does not only allow to personalise the learning process for each user, but also to quantify how difficult a particular word is in general: without going into nitty-gritty details, in their regression formulation, the half-life of a word can be seen as a multiplication (in the log-space) between the word weights (or features) and the user weights (or features). With the fixed user features, the larger the word weight, the longer the duration of the half-life cycle of the word in memory, hence positive weights imply easier to remember words, while negative weights – harder to remember words.
I have also found two US patents assigned to Duolingo that are listed as abandoned: “Automatic Test Personalisation” and “Interactive sponsored exercises”. The first patent explains the concept of a video recording interview, where the user is prompted to answer a set of questions. The recorded answers are then graded by the system to provide the proficiency score of the user, and send through to a reviewer. Questions can be one of "text-based question prompt, an audio question prompt, and a video question prompt." The system is also responsible for selecting the questions that would serve as a good indicator of the user proficiency on a certain subject. To get quantitative results, the system analyses what sorts of mistakes the user commits: it "analyzes the response to determine what errors the user made (e.g., a typo, a grammatical mistake, selection of the second best answer in a multiple choice, a calculation error) and uses the error type to determine the user proficiency level. For example, a simple typo will result in the user getting most of the credit in a translation exercise, while multiple grammar and vocabulary mistakes will result in a low amount of credit.".
The second patent goes into the details of describing the process of including advertisements within the learning process as succinctly visualised on the figure below. "For example, a sponsor could submit a question for a trivia game, such as “What new color of M&M was introduced in 1995 in response to the Color Campaign” with options of “Yellow”, “Green”, “Pink,’ and “Blue.”" or "a user is asked “What do you want to eat?”, and as a prompt a box of Dominos pizza is presented. A correct response (if the user was learning English) would be to respond in English with “I want to eat pizza”, or even “I want to eat some Domino's)." Essentially, it it still the same teaching system but with the caveat of also including some sponsored content and analysing the reaction of users to it.
 |
|---|
| Example of advertisements within app. Picture from Duolingo patent |
In conclusion, while the Duolingo patents do not seem to be directly related to automatisation of the learning process, their AI team and research papers show a strong incline towards machine learning-based technologies. As in the case of Lingualeo, it would be interesting to know to what extent they still rely on manual instructions in their system, and how recent advances are being used in their products.
Fun fact: Duolingo was founded by one of CAPTCHA creators, Luis von Ahn
Final words
I started this post by labelling myself as a strong believer of the concept of learning from intelligent machines. So what can we learn, if anything, from the technological advances featured in the four stories above? The most obvious use case, of course, is learning foreign languages: both Lingualeo and Duolingo facilitate this process by meticulously tracking the learning progress and adapting the curriculum on-the-fly. For example, Duolingo’s half-regression approach models forgetting curves for different words and users.
What then can we learn from the technologies developed at Thinkster Math and Gradescope? As things stand, not much, but I must be clear here as their products serve a different purpose: instead of explicitly teaching, they facilitate some underlying issues for tutors – i.e., tracking of thinking process of students in the former case and grading of students’ works in the latter one. They help tutors by providing more information and automatising the process. Can we build machines that would not only enlarge tutors’ stack of technology, but also teach tutors how to become better educators and how to improve their grading strategies? Can the machines be used to spot what tutors missed in the learning process in the way that it would prevent such a miss in the future? I believe we can, but we are not there yet.
I am thankful to Nathan Walsh for his comments on the first draft of this article, among which was “it’s fascinating”.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Comments